From Strings to Things: Knowledge-enabled VQA Model that can Read and Reason
Ajeet Kumar Singh, Anand Mishra, Shashank Shekhar, Anirban Chakraborty
ICCV 2019
[Paper][Supplementry Material][Slides][Poster]

Motivation
Text present in images are not merely strings, they provide useful cues about the image. Despite their utility in better image understanding, scene texts are not used in traditional visual question answering (VQA) models. In this work, we present a VQA model which can read scene texts and perform reasoning on a knowledge graph to arrive at an accurate answer. Our proposed model has three mutually interacting modules: (i) proposal module to get word and visual content proposals from the image, (ii) fusion module to fuse these proposals, question and knowledge base to mine relevant facts, and represent these facts as multi-relational graph, (iii) reasoning module to perform a novel gated graph neural network based reasoning on this graph.
The performance of our knowledge-enabled VQA model is evaluated on our newly introduced dataset, viz. textKVQA. To the best of our knowledge, this is the first dataset which identifies the need for bridging text recognition with knowledge graph based reasoning. Through extensive experiments, we show that our proposed method outperforms traditional VQA as well as question-answering over knowledge base-based methods on text-KVQA
Contributions
- Drawing attention to reading text in images for VQA tasks.
- Introducing a large-scale dataset, namely text-KVQA.
- A VQA model which seamlessly integrates visual content, recognized words, questions and knowledge facts.
- Novel reasoning on mutli-relational graph using a GGNN formulation
Dataset

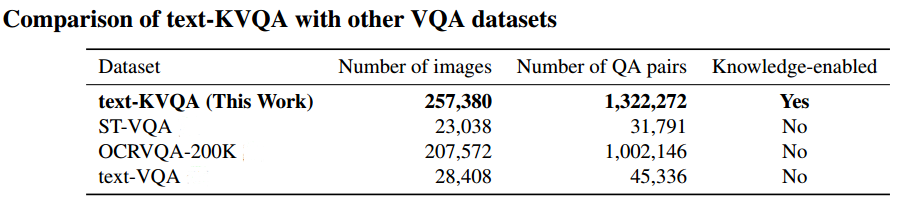
Dataset Downloads
- Dataset images and QA Pairs
- text-KVQA (scene) [Images [14.6 GB], QA Pairs]
- text-KVQA (book) [Image URLs and QA Pairs]
- text-KVQA (movie) [Image URLs and QA Pairs]
- Knowledge Bases
Bibtex
If you use this dataset, please cite:
@InProceedings{singhMSC19,
author = "Singh, Ajeet Kumar and Mishra, Anand and Shekhar, Shashank and Chakraborty, Anirban",
title = "From Strings to Things: Knowledge-enabled VQA Model that can Read and Reason",
booktitle = "ICCV",
year = "2019",
}
Publications
Ajeet Kumar Singh, Anand Mishra, Shashank Shekhar, Anirban Chakraborty, From Strings to Things: Knowledge-enabled VQA Model that can Read and Reason, ICCV 2019 [pdf][Supplementary][Slides][Poster]